
I am currently a researcher at the Augmented Vision department at DFKI (German Research Center for Artificial Intelligence), specializing in computer vision and deep learning. My work centers on 3D scene understanding and neural rendering, with a growing interest in world models that enable machines to build structured, semantic, and interactive representations of complex environments.
I hold a Master’s degree in Computer Science from RPTU Kaiserslautern, where I graduated with distinction and my thesis focused on Open-Vocabulary 3D Scene Understanding with Gaussian Splatting. Prior to that, I completed my Bachelor’s in Computer Science and Engineering at the German University in Cairo, graduating ranked among the top students in my cohort.
Publications

ReLaGS: Relational Language Gaussian Splatting
CVPR 2026 Yaxu Xie*, Abdalla Arafa*, Alireza Javanmardi, Christen Millerdurai, Jia Cheng Hu, Shaoxiang Wang, Alain Pagani, Didier StrickerWe present a novel framework that constructs a hierarchical language-distilled Gaussian scene and its 3D semantic scene graph without scene-specific training, enabling efficient and scalable open-vocabulary 3D reasoning by jointly modeling hierarchical semantics and inter/intra-object relationships.

GHOST: Fast Category-agnostic Hand-Object Interaction Reconstruction from RGB Videos using Gaussian Splatting
CVPR Findings 2026 Ahmed Tawfik Aboukhadra, Marcel Rogge, Nadia Robertini Abdalla Arafa, Jameel Malik, Ahmed Elhayek, Didier StrickerGHOST is a fast, category-agnostic framework for reconstructing hand-object interactions from monocular RGB videos using 2D Gaussian Splatting. It represents hands and objects as dense Gaussian discs and uses geometric priors, grasp-aware alignment, and hand-aware background loss to produce physically consistent, complete, and animatable 3D reconstructions.
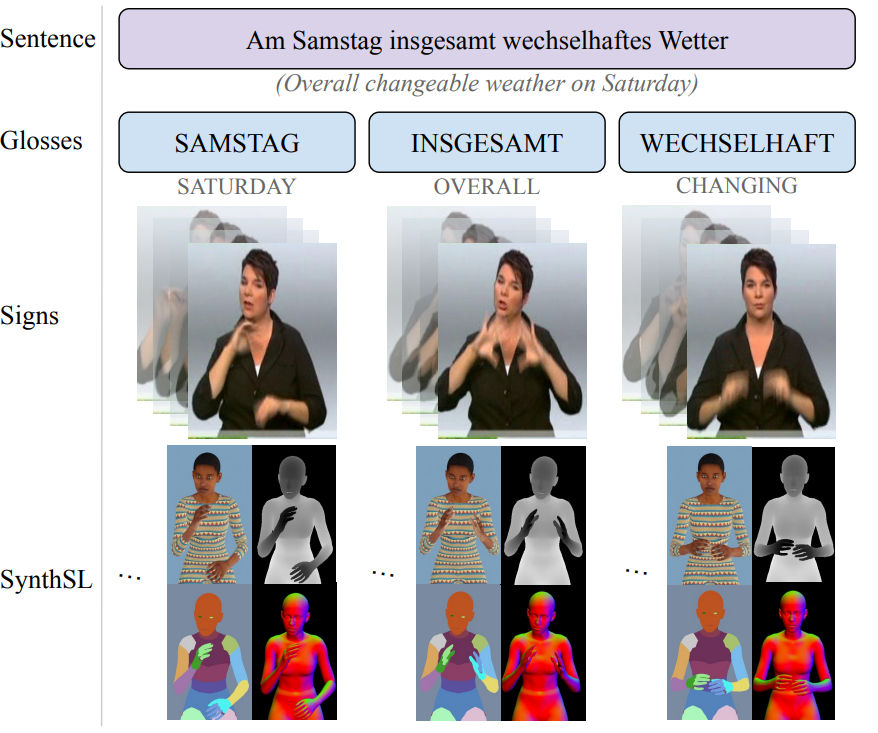
SynthSL: Expressive Humans for Sign Language Image Synthesis
IEEE FG 2024 Jilliam M. Díaz Barros*, Chen-Yu Wang*, Jameel Malik, Abdalla Arafa, Didier StrickerWe introduce SynthSL, a large-scale synthetic dataset for sign language production, recognition and translation, along with a rendering pipeline based on the SMPL-X body model. We additionally propose a new Swin Transformer-based generator for sign image synthesis conditioned on body pose and appearance.